HomePage » Fraud Detection (3) Combining Neo4j with Machine Learning to Predict Financial Fraud
Author | Tangwei Hung
Combining Neo4j with Machine Learning to Predict Financial Fraud
Contents
Machine Learning for Fraudster Prediction
In this chapter, we will leverage the machine learning tool provided by GDS to predict the probability of a client as a fraudster.
Let’s walk through the process with the following steps:
Add labels to the fraudsters
Add more properties as features (feature-engineering)
Use FastRP as node embedding
Train and test the model
Make prediction
1. Label the fraudsters
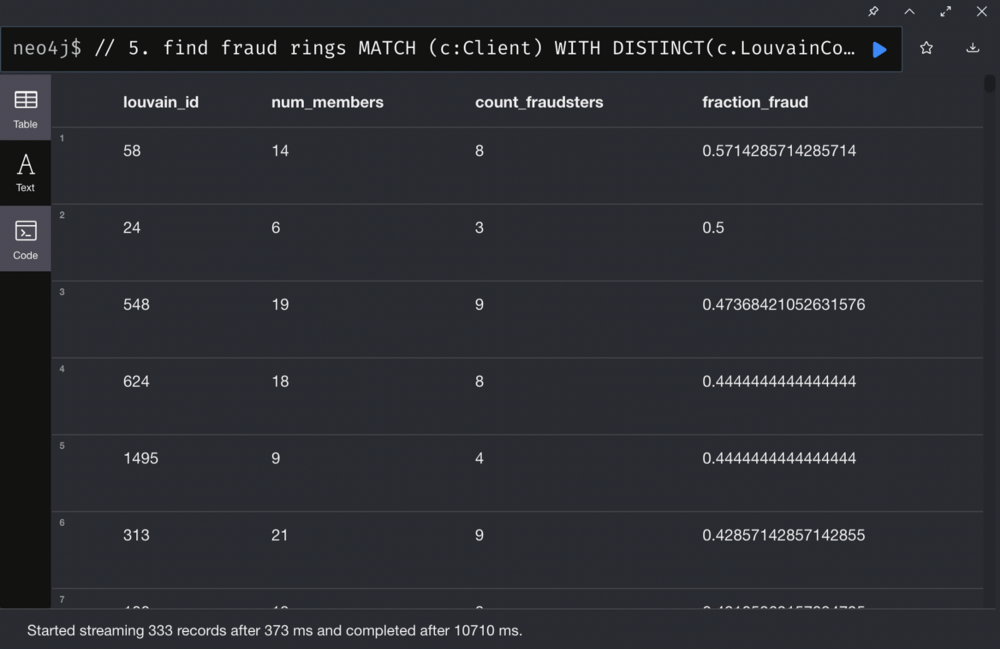
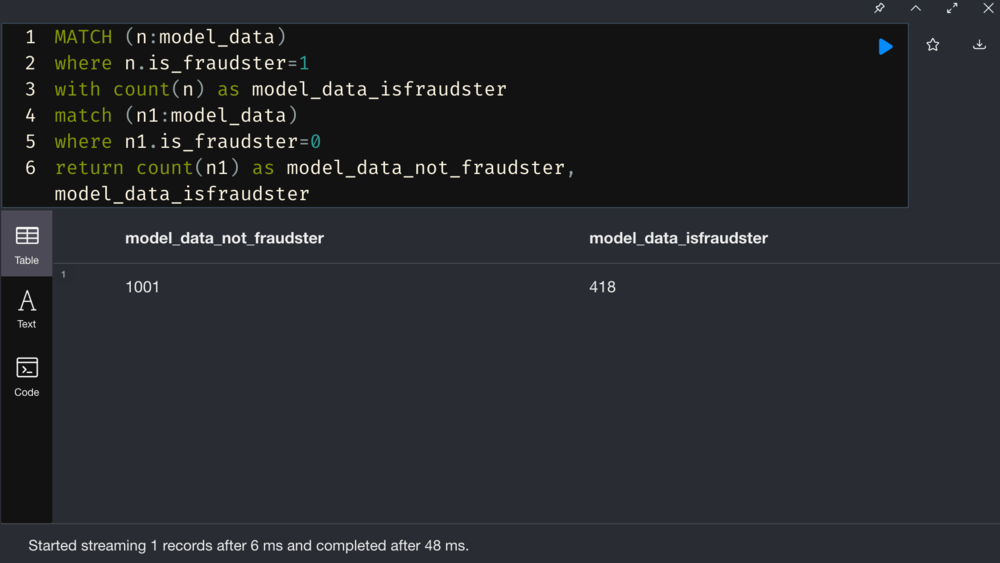
We need to provide data with labels as training data for the computer; since labeling data is not available in PaySim, let’s make a hypothesis that clients who have participated in more than 10 fraudulent transactions have a high probability as fraudsters, and we label them as fraudsters. We also mark add labels to the suspects we identified in the previous chapter as fraudsters.
On the other hand, we use the Lovain algorithm to group clients. For clients with the fraudster probability of less than 0.065, we mark them as non-frauds.
Calculate Fraud fraction
2. Add more features
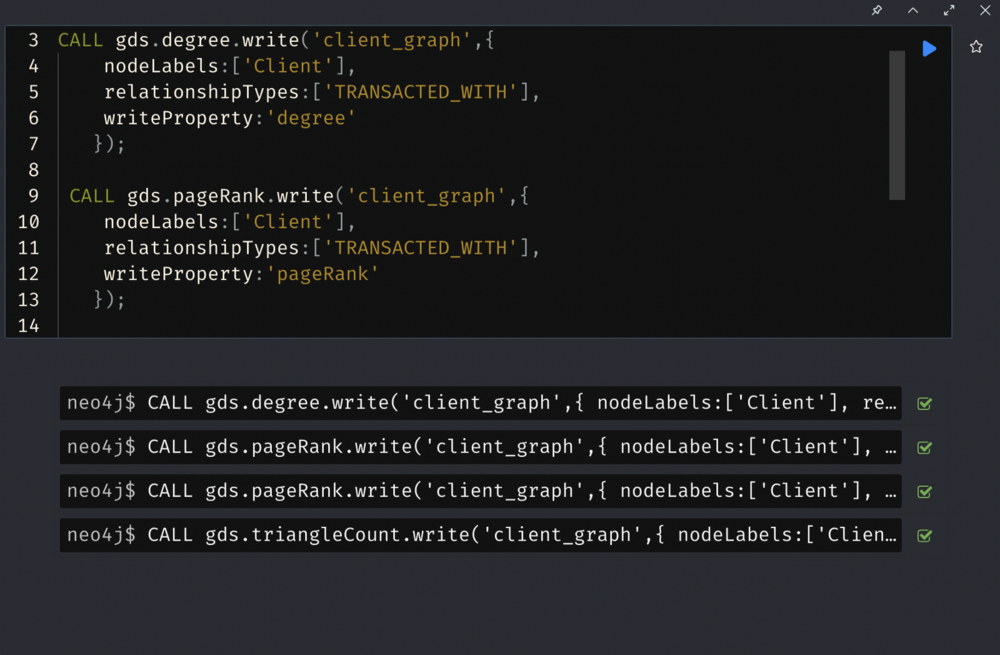
We use Degree, Page Rank and Triangle Count in GDS to add more features to the nodes.
Add more features
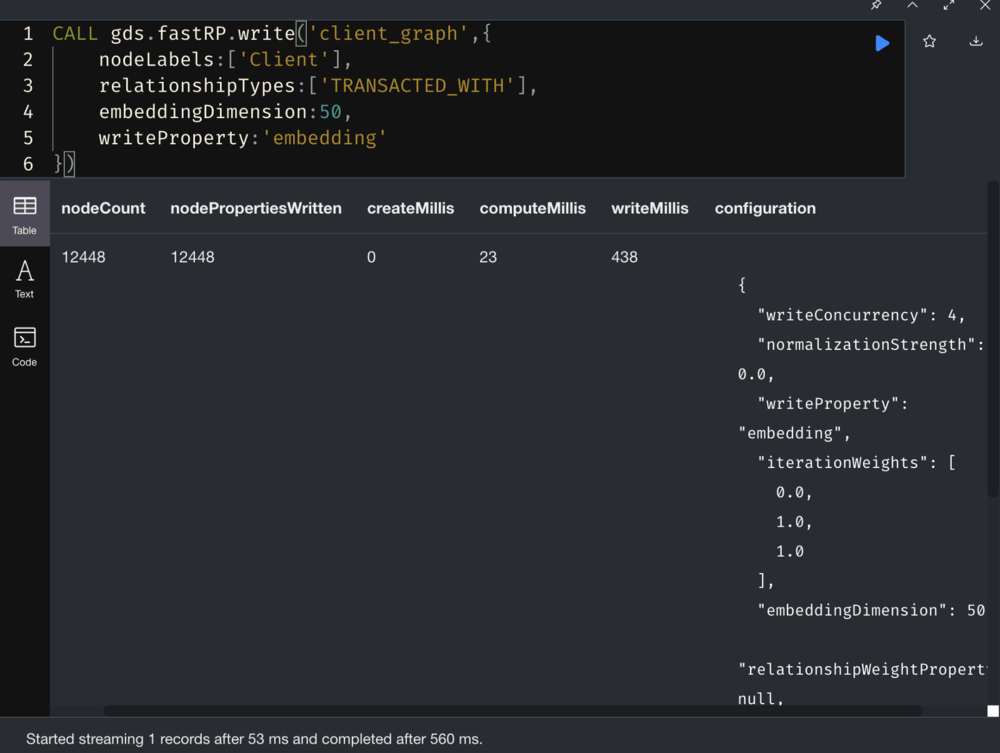
3. Use FastRP for node embedding
Use FastRP in GDS to vectorize the nodes, and add the vectorization between the nodes to the node features.
Calculates the nodes of low-dimensional vector in the graph with the Node Embedding algorithm. These vectors, also called embeddings, can be used for machine learning.
Fast Random Projection (FastRP) is a kind of node embedding algorithm in random projection algorithms. We can project n vectors of any dimension into O(log(n)) dimensions and still maintain the pairwise distance between nodes.
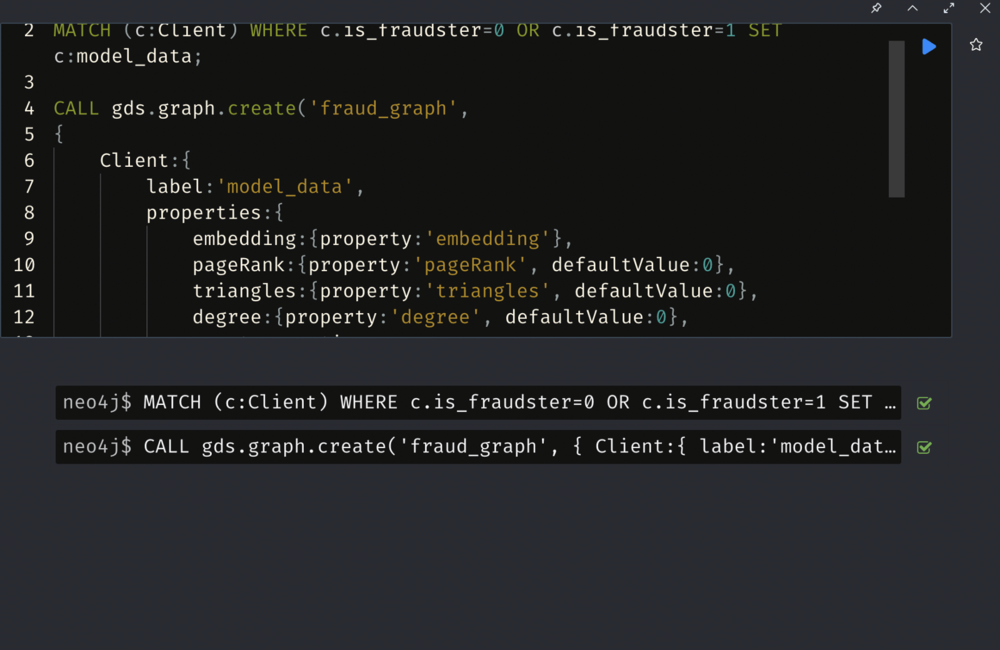
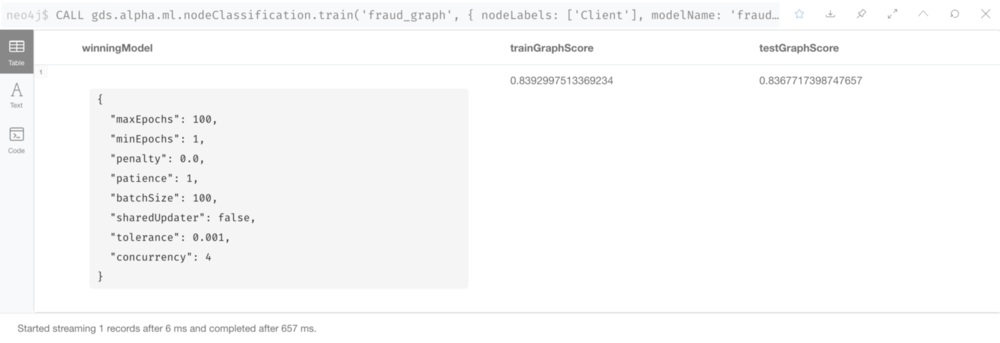
Here we create our prediction model and train this model, and then test the accuracy of the model.
Create Model
Train and Test Model
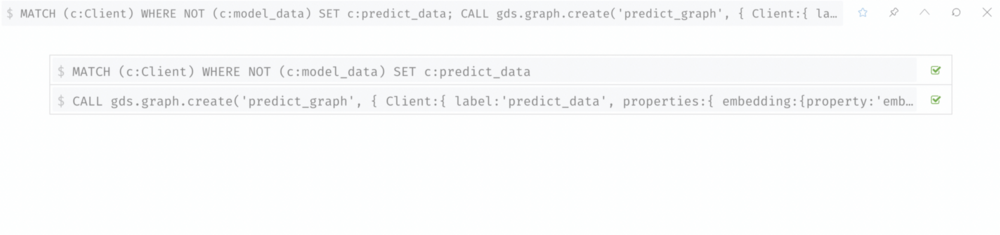
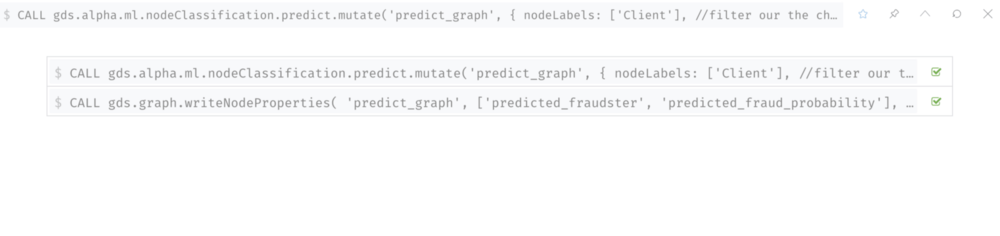
5. Make prediction
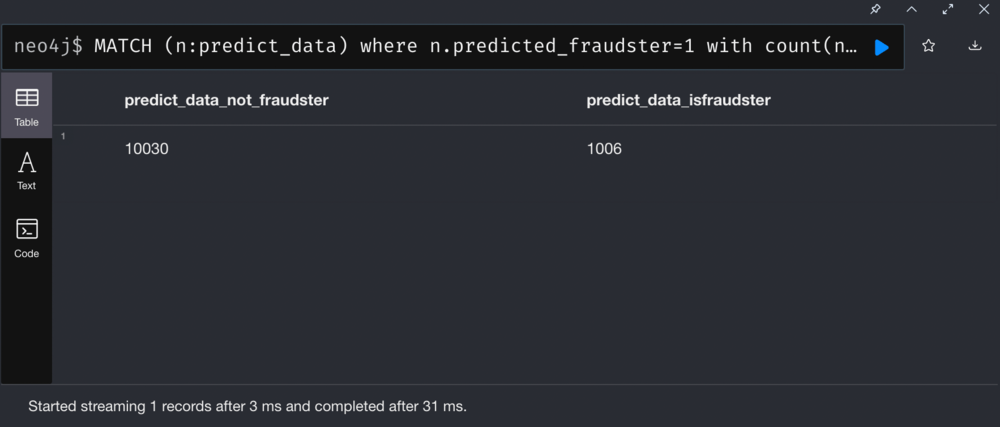
In this step, we label the clients without labels, and use the model to predict the probability of fraudsters for these clients.
Label the data we want to predictions on
Make the prediction and write to the database
Possible Fraudster
Let's Summarize the Second Part: What Have We Done?
In a nutshell, we use GDS to build a model and predict the probability of frauds:
We label and distinguish clients as fraudsters and non-fraudsters, and use the Lovain algorithm.
Feature engineer (Use Degree, Page Rank and Triangle Count in GDS to add more features to the nodes.)
Node embedding using FastRP algorithm
Train and test the model
Use the trained model to predict the unlabeled clients in the graph
The major difference between using Neo4j ML and the classic ML is that we can use the Graph Algorithm in Neo4j such as Centrality or Node Embedding to add features in the graph. In short, we increase the accuracy of the model by introducing more graph-based features to in feature engineering.